
Predicting Good Loans on LendingClub
For my third project, I looked at classifying LendingClub.com loans as either defaulted on or fully paid off. Lending Club is a crowdfunding loan website that allows borrowers to get loans at rates lower than banks, and investors to invest in those loans and get pretty good returns. I wanted to build a model from the perspective of an individual investor investing in loans.
Obtaining and Looking at the data
I got the data from Kaggle and removed any of the rows that were current loans and removed any columns whose values would not be determined before a loan is funded. This left me with about 25 features and 200,000 rows. Most of the features that Lending Club/Kaggle provided were things having to do with credit history (# of inquiries, total amount of credit accounts, etc.) and other personal information (reason for loan, salary, length of employment history, etc.).
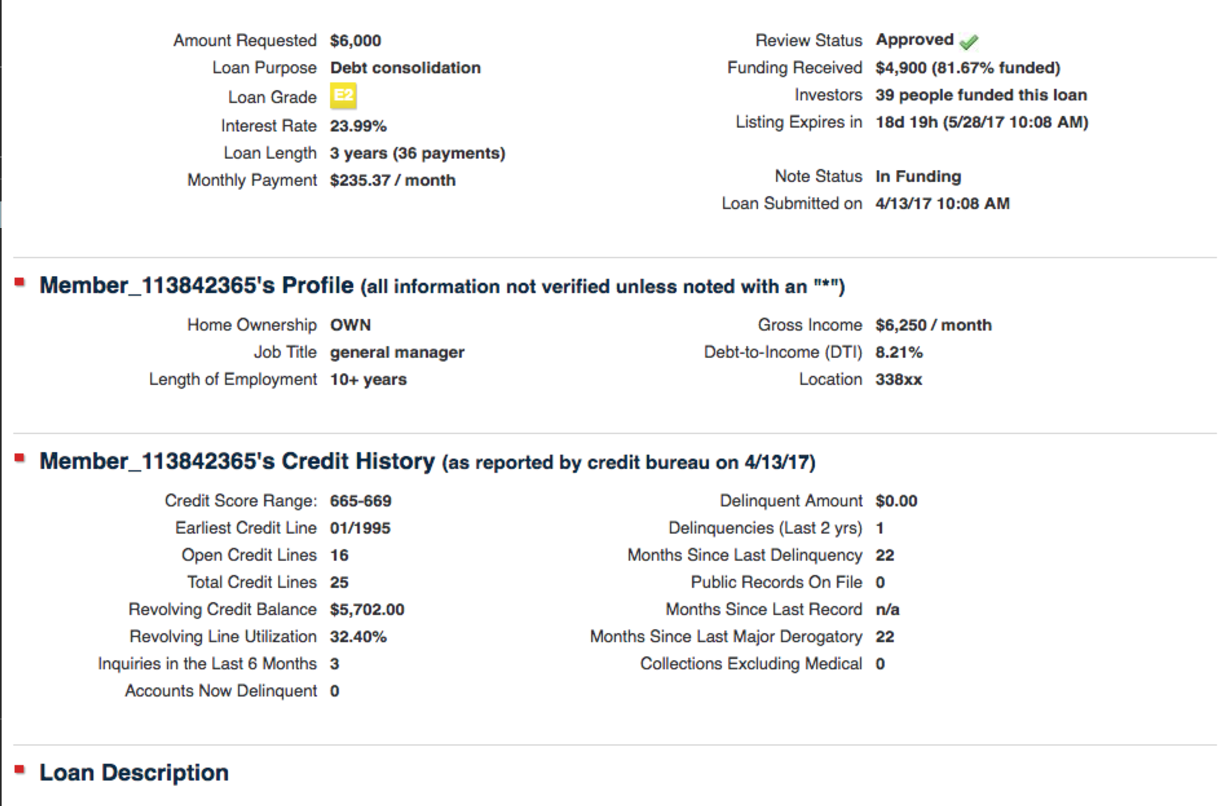
I had looked at Lending Club years ago, and have a relatively good understanding of credit and loans, but I still had to spend a good amount of time researching what all the features stood for and how relevant they would be if someone would pay off a loan or not.
Thankfully, this data was already pretty clean, so not much cleaning was necessary. There were some columns that were almost all nulls so they were deleted. For some of the columns, like revolving credit utilization, which I thought was important, I replaced the nulls with the mean of that column.
Next, it was time to visualize the data:

Lending Club labels each loan with a grade from A-G that is supposed to signify risk, and, according to the graph, it looks like Lending Club does a pretty good job.
I also looked at some features that I thought would definitely be related to a loan defaulting or not, like the borrower’s annual income:
Like I guessed, people with higher incomes tend to pay off their loans more.
I also looked to see if the state a person was from was correlated with them defaulting or not:
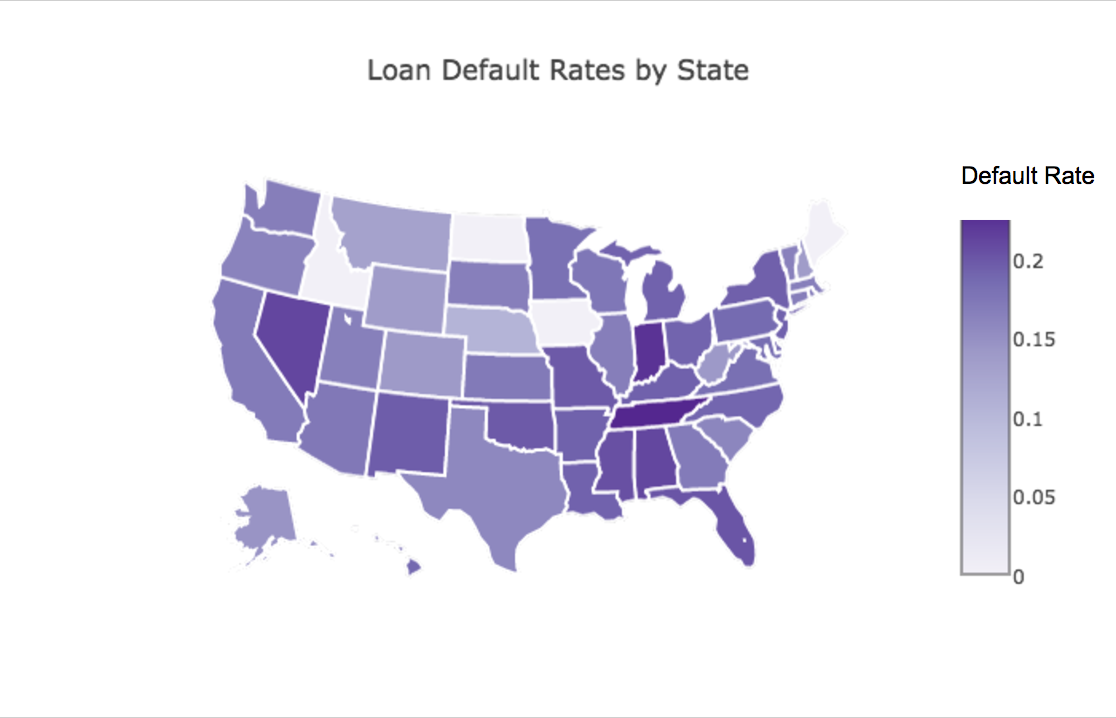
Indiana had the highest default rate, and many states in the South tended to have higher default rates, especially compared to the upper West.
Modeling
Because my data cleaning process was quick I decided to spend a lot of time on modeling. I ran Scikit-Learn’s GridSearchCV with many classifying algorithms like: K Nearest Neighbors, Logistic Regression, Random Forests, and Linear Support Vector Machines. All led to an accuracy of about 82%. Which sounds good, except for the fact that 82% of people in my data paid off their loans—meaning that the accuracy was just predicting everyone would pay off their loans.
I decided to downsample my Fully Paid class to equal that of my Defaulted class in the training set and reran GridSearch with a bunch of estimators. Though my accuracy dropped to 65%, my precision for the Fully Paid class jumped from .82 to around .91 (depending on the estimator). This result is what I wanted to happen, as my model was made from the perspective of an individual investor. An individual investor, unlike a bank, only has a finite amount of money to invest in and is going to be especially sensitive to losses. Even with a high precision and low recall, my model is set up to still say “Yes” on 800-1000 loans a year, which should be plenty for an individual investor.

Most of the estimators I used had a similar precision-recall curve, but, by a very small margin, the gradient boosted trees classifier did the best.
Loan Picking App

I decided to have fun and create a small Flask app that would determine if someone should invest in a loan or not. Since I don’t think anyone would want to input a bunch of variables into the app, I choose the seven strongest features.
The app is powered by Logistic Regression and set to only give a “Yes” for an investment if the probability of that loan being in the “Fully Paid” class was over 70%. I tested that percentage, and that percentage gave about a precision rate of about 95%—which is a perfect balance of having low risk but also leaving enough loans to invest in for an individual investor.
Further Research/Improvements
- Lending Club has provided a 2016 loan dataset that I would like to add to my model too. In that year, they also added credit score, which I would like to see if could help gain further insight to loan defaulting.
- I would also like to try my model on different crowd funding loan sites, like Prosper, to see if my model generalizes.
- Finally, I would like to make my app more pretty and also account for how much risk a person wants to take (and maybe create a second model on the riskiest loans).
Final Thoughts
-
If you can take risks, take them. For my presentation, I took a gamble and presented my model as something I was selling, like in an infomercial. I thought trying to combine humor with data might not work so well, but I tried it anyways, and it was well received.
-
Flask is amazingly easy to use. I was able to build, troubleshoot and get a basic app running in about 4-5 hours. I worked on this the day before my project was due, and didn’t think it would be ready for my presentation. However, I was able to follow and modify much of the code I saw in tutorials like TutorialsPoint to make something surprisingly workable. Yes, it is not pretty—however, it does what it needs to do.
Interested in the code or presentation for this project? Take a look at my GitHub.